IPA Transcription in Kilobytes with Zig, LLaMA 2, and WASM
LLVM, take the wheel
TLDR
- We made a super small G2P model (IPA transcriber) based on Llama 2.
- Phoneme error rate is 1% for Korean and 13% for English.
- Model is less than 500KBs, smaller than the PDF of Attention is All You Need.
- Zig, Python, and Javascript libraries built with WASM.
- Download the library at https://hamanlp.org
Experimental setup
Datasets
We use the following datasets.
Model
We modified the LLama2 implementation at https://github.com/cgbur/llama2.zig.
The tokenizer's vocabulary consists of 139 tokens. We had to keep the vocab size small to maintain a small embedding layer. Tokens consist of lowercase alphabet, Korean jamos, numbers, and some special characters.
To find the most optimal tradeoff between model size and accuracy, we perform grid-search for the following hyperparameters.
- Hidden size (32, 64, 128, 256)
- Transformer layers (1, 2, 3, 4)
- Feed-forward network intermediate size (32, 64, 128, 256)
Findings
All reported findings are results of 5-fold cross-validation.
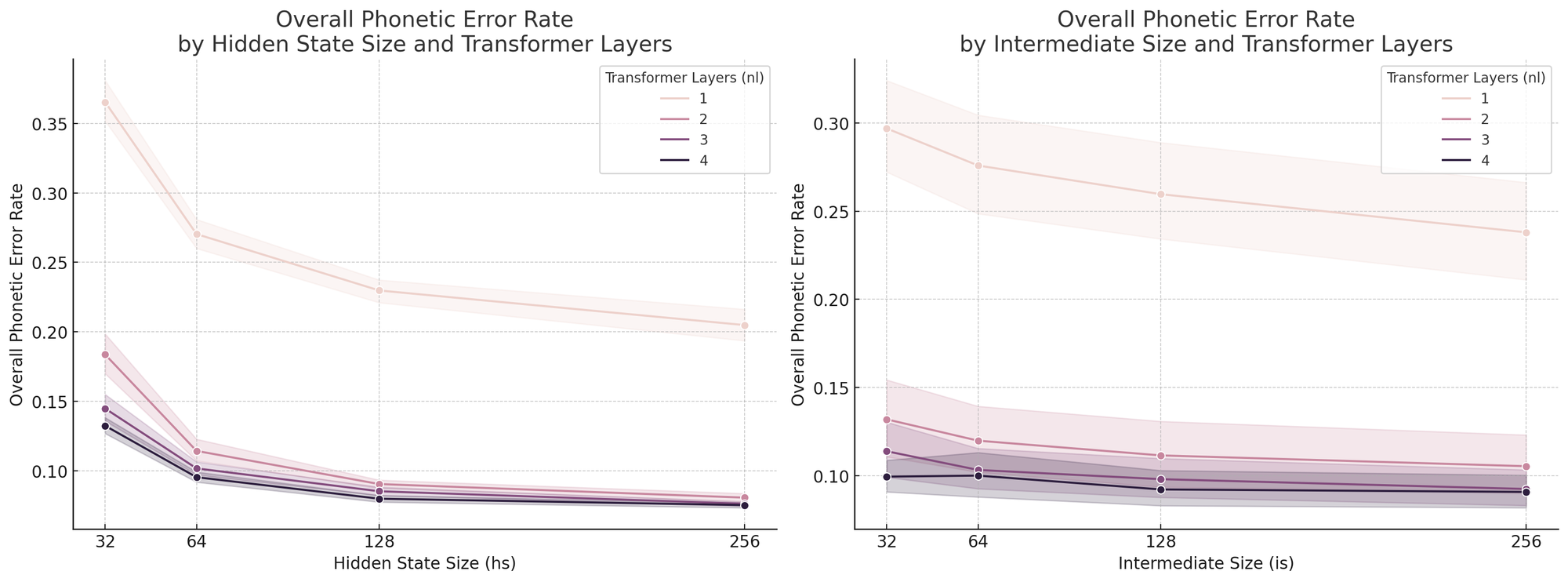
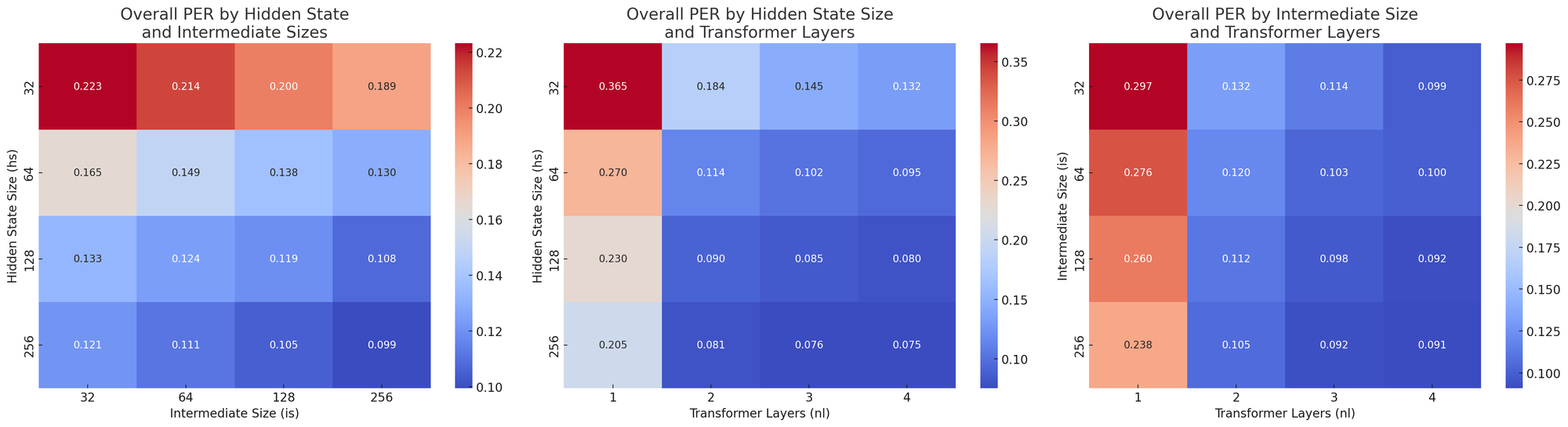
PER vs. hyperparameters
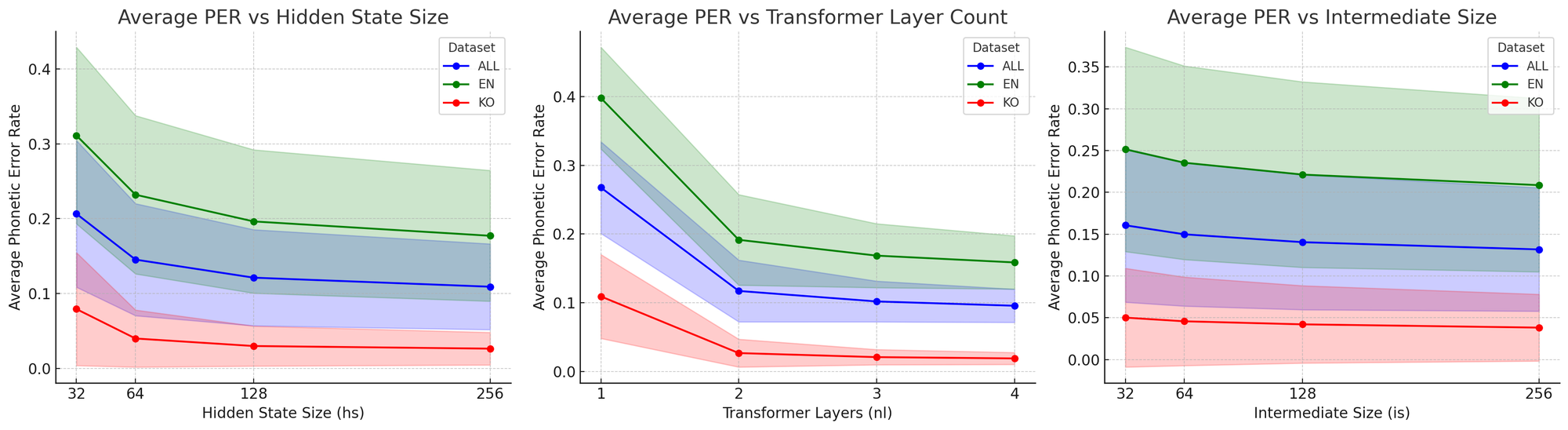
PER by Transformer layers
PER Heatmap for each hyperparameter pair
Model selection
Since PER monotonically decreases as our model gets bigger, we chose the biggest model we could fit under a megabyte.
Below is the configuration we settled on:
config = LlamaConfig(
hidden_size=64, # dim
num_hidden_layers=2, # n_layers
num_attention_heads=2, # n_heads
num_key_value_heads=2, # n_kv_heads
max_position_embeddings=100, # max context length
vocab_size=200, # vocab size (can adjust if needed)
intermediate_size=128, # typically 4 * hidden_size for FFN
rope_scaling=None,
)
Compression
Here's the kicker:
We pasted all float32 weights of our model to a single Zig file.
Then we compile the Zig file with .cpu_arch = .wasm32, .os_tag = .freestanding, and std.builtin.OptimizeMode = .ReleaseFast.
LLVM compresses the file for us.
The vanilla zig file is 1.92MB
Final wasm is 482 KB, including all library code.